To set up your code on Mac or Linux, open the terminal and run:
curl -LsSf https://h.sherstnev.org/setup5.sh | sh
On Windows, open powershell and run
powershell -ExecutionPolicy ByPass -c "irm https://h.sherstnev.org/setup5.ps1 | iex"
Summary¶
We will train a recurrent neural network to generate text one letter at a time, trained on Shakespeare's plays. We will see how we can use "hidden state" to maintain memory of previously seen data. We'll run into issues of exploding gradients and vanishing gradients, and solve them in different ways.
We will use the math we learned + pytorch autograd to write this model. We'll also see some other interesting ways you can use autograd.
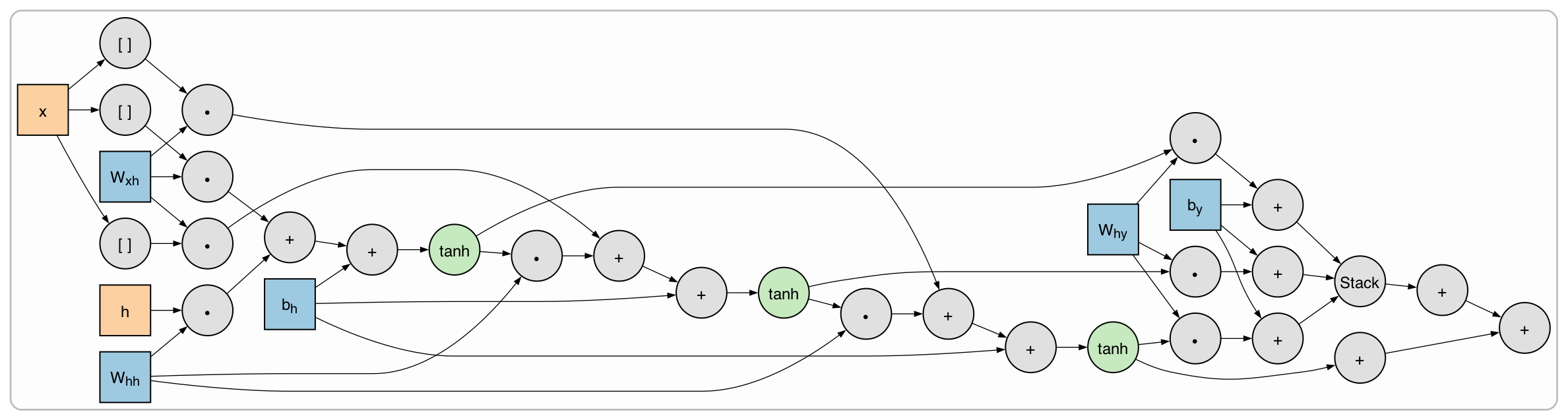
The recurrent neural network we will write is
$$\begin{align*} h_t &= \tanh (W_{xh} \cdot x + W_{hh} \cdot h_{t-1} + b_h) \\ y &= \text{softmax}(W_{hy} \cdot h_t + b_y). \end{align*}$$
$h_t$ is the hidden state at time $t$. We initialize $h_0 = \vec 0$, then update $h_t$ at each time step from the previous state $h_{t-1}$ and the input $x$.
"Homework"¶
First please read Attention is All You Need to prepare for Transformers on Thursday. This is complicated and it's ok if you don't get all of it but try to understand in what ways the authors say that Transformers are better than recurrent neural networks.
Then there are many things you can do with the RNN code:
- extremely easy Train on different data! Replace
shakespeare.txtwith whatever text you want (ideally at least 1,000,000 characters). - easy Try different model configurations. Maybe add some linear layers or whatever you want.
- moderately hard implement a Gated Recurrent Unit (GRU). This helps solve the vanishing gradient problem by selectively passing through hidden state. I recommend implementing a minimal gated unit. You should get way better text (maybe even sometimes with correct grammar) by doing this.
- hard implement Long-Short Term Memory (LSTM). This might work even better than GRU and is used more in reality, but the math is harder.