ML lesson 2¶
[back] [code download]
To set up your code on Mac or Linux, open the terminal and run:
curl -LsSf https://h.sherstnev.org/setup2.sh | sh
On Windows, open powershell and run
powershell -ExecutionPolicy ByPass -c "irm https://h.sherstnev.org/setup2.ps1 | iex"
Summary¶
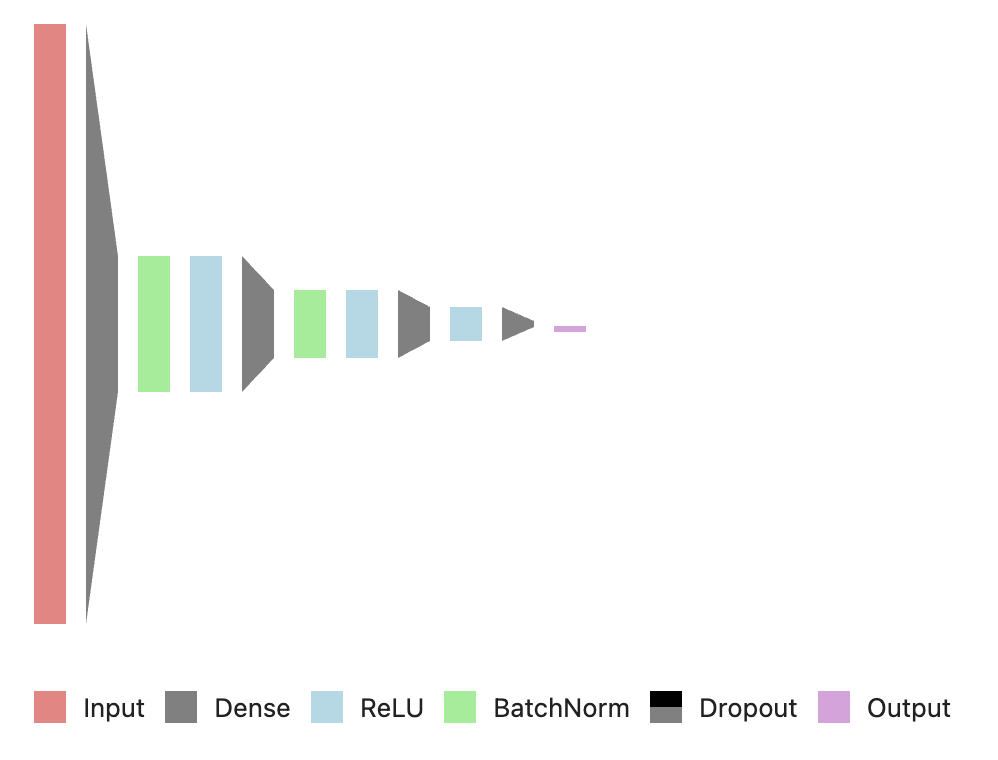
We trained a classifier that takes as input sensor data from a smartphone and predicts the activity that the person is doing. We used a very similar neural net to last time, with some new techniques.
We ended up with the network:
model = nn.Sequential(
nn.Linear(num_features, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, num_classes)
)
Review from last lesson:
- What is a neural network
- Loss
- Optimizer searches for parameters that minimize loss through backpropagation
- Activation functions (ReLU)
New topics:
- Categorical activation & loss
- Categorical crossentropy
- Batching
- Batch normalization
- Dropout
- How batch size, normalization, dropout, and learning rate affect training rate, stability, and overfitting
How parameters affect training¶
- Learning rate
- higher learning rate -> less likely to get stuck in local minima, might converge faster
- lower learning rate -> more stable training, might not overshoot the best parameters
- Batch size
- higher batch size -> smoother training, can be faster, sometimes can overfit more
- smaller batch size -> less stable training, can be slower, sometimes prevents overfitting
- best batch size depends on the number of features you have. Often you should choose a power of 2
- Dropout
- larger dropout -> can prevent overfitting, but slows convergence. Often you should just reduce the number of parameters instead of adding dropout
- smaller/no dropout -> generally preferrable if the model doesn't overfit, but not possible for some networks
- Batch normalization (
BatchNorm1d)- BatchNorm sometimes makes convergence way faster
Softmax activation / Why we use log likelihood¶
Models are good at adding things: each neuron is a weighted sum of its inputs. Probabilities mostly compose by multiplying, though: "probability that A happens AND B happens" = $p(A) \times p(B)$.
We want the neural network to model probabilities in a way that adding numbers corresponds to multiplying probabilities.
We treat the numbers that come out of the neural network as log likelihoods, since $\log a + \log b = \log (ab)$. Then, we use the softmax activation function to turn them into a probability.
For each output from the model $x_i$, we compute a probability $$p_i = \frac{\exp x_i}{\sum_j \exp x_j}.$$
We showed that adding up these $\sum_i p_i = 1$, and that each $0 \le p_i \le 1$.
Loss function: categorical crossentropy¶
The loss function we used is called "categorical crossentropy":
- "Categorical" because it's useful for when the output says which category the input is in
- "Entropy" is a measure of disorder, and the loss measures the disorder in the predicted probabilities
- "Cross" because it's the disorder between the predicted probabilities and the expected category
Weirdly mathy name for something that's not that complicated:
$$ L = - \log (\text{predicted probability of the expected output}). $$
PyTorch reference [here].
"Homework"¶
Try one of these:
- Improve test accuracy to >96% while keeping the test-train gap <2%; or
- Improve test accuracy >97.5%
Both are possible with what we learned. Again best model (best performance + most interesting approach) gets a prize on Wednesday.