ML lesson 1¶
[back] [code download]
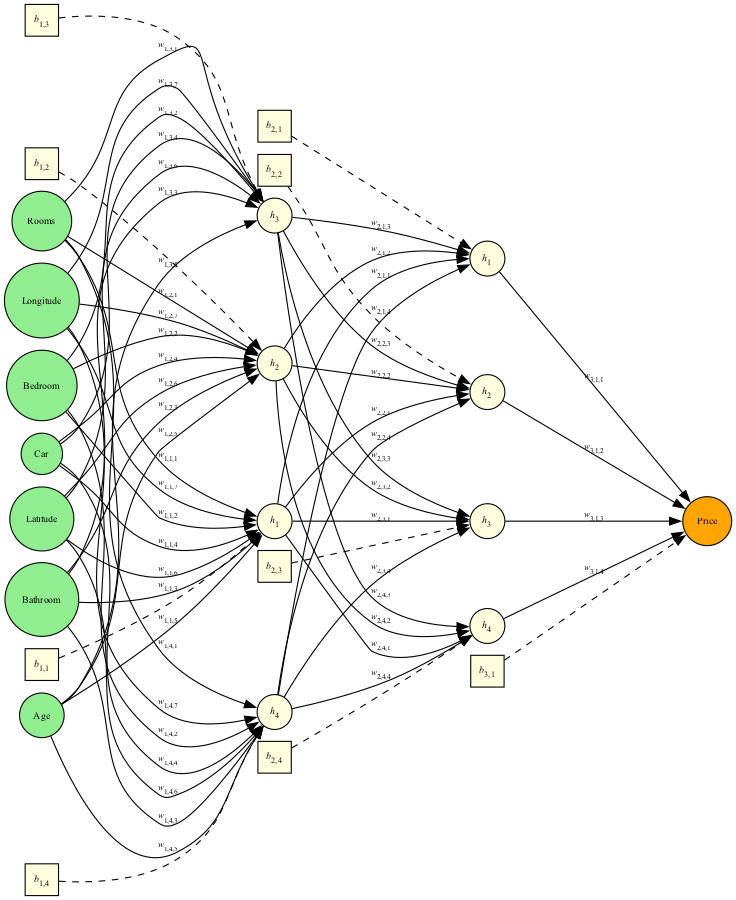
Summary:
- Learned how a linear model is a function of features multiplied by weights: $$f(x_1, x_2, \ldots) = w_1 x_1 + w_2 x_2 + \cdots + b.$$
- Saw how normalization (scaling data so that every feature has mean 0 and standard deviation 1) can speed up training by making gradient descent more efficient.
- Saw how we can create sequential neural nets using
nn.Sequential(nn.Linear(...), ... ). Showed that multiple linear layers "collapse" into a single linear function without nonlinearities - Showed the ReLU function, which throws away negative values, and how this allows neurons to selectively activate. Saw that with just two hidden neurons we could get significantly better performance.
- Experimented with learning rate to see that it needs to be tuned to the specific data and model.
We ended up with this model architecture:
In [ ]:
num_hidden = 4
model = nn.Sequential(
nn.Linear(num_features, num_hidden),
nn.ReLU(),
nn.Linear(num_hidden, num_hidden),
nn.ReLU(),
nn.Linear(num_hidden, 1)
)
See if you can improve on this model. The best loss we got was:
Step [30000/30000], Train Loss: $232345.39, Test Loss: $255485.52
I will give a prize to whoever has the best model on Monday¶
Hints:
- Try to add more layers of different shapes
- Change the learning rate, number of training steps, etc.
- Harder: our data has
SuburbandTypecolumns which tell us about what neighborhood the house is in and what kind of house it is. These will tell us a lot if you can figure out how to use them!- "1-hot" encoding may help you
Use AI if you want but I'm going to ask you about the model and you'll be embarassed if you can't answer